Process API újítások
Előzmények
A Java korai verzióiban elég nehézkes volt új folyamatot indítani. Ehhez csak a Runtime.getRuntime().exec() metódus állt rendelkezésünkre. 2004-ben, a Java 5 megjelenésével ez megváltozott, innentől kezdve elérhetővé vált a ProcessBuilder API, amivel könnyebben lehetett létrehozni új folyamatokat. Nézzük meg, hogy mivel bővül a process API repertoárja a Java 9-ben!
ProcessHandle interfész
Az új ProcessHandle interfész új lehetőségeket nyit számunkra a natív folyamatok kezeléséhez. A Java 5 óta elérhető ProcessBuilder által előállított Process objektumoktól elkérhető azok ProcessHandle-je.
A ProcessHandle feladata, hogy azonosítson egy folyamatot és lehetővé tegye, hogy különféle műveleteket végezzünk el rajta. Példányok a következő statikus factory metódusok segítségével hozhatók létre:
| Statikus factory metódus | Létrehozott ProcessHandle objektum |
| current() | Az aktuális folyamathoz tartozó ProcessHandle objektummal tér vissza. |
| of(long pid) | Optional<ProcessHandle> objektummal tér vissza, ami a megadott natív folyamat azonosítóhoz tartozik. |
| children() | Stream<ProcessHandle> objektummal tér vissza, ami az aktuális folyamathoz tartozó közvetlen gyerek folyamatokat tartalmazza. |
| descendants() | Stream<ProcessHandle> objektummal tér vissza, ami az aktuális folyamathoz tartozó gyerek folyamatokat tartalmazza, rekurzívan azok gyerek folyamataival együtt. |
| parent() | Optional<ProcessHandle> objektummal tér vissza, ami az aktuális folyamat szülő folyamatát tartalmazza. |
| allProcesses() | Egy olyan Stream<ProcessHandle> objektummal tér vissza, ami az aktuális folyamat által látható össze folyamat ProcessHandle-jét tartalmazza. |
További hasznos metódusok, amit a ProcessHandle interfész elérhetővé tesz:
| ProcessHandle metódus | Leírás |
| info() | ProcessHandle.Info objektummal tér vissza, ami az adott folyamathoz tartozó információkat tartalmazza. |
| isAlive() | boolean-nel tér vissza, ami azt jelzi, hogy az adott folyamat él-e még. |
| pid() | A natív folyamat azonosítóval tér vissza, ami alapján az operációs rendszer számon tartja az adott folyamatot. |
| supportsNormalTermination() | boolean-nel tér vissza, ami azt jelzi, hogy támogatja-e a normál leállítást az adott folyamat, vagy rákényszerítve, azonnal állítja le a folyamatot. |
| onExit() | CompletableFuture<ProcessHandle> objektummal tér vissza, ami arra használható, hogy az adott folyamat befejeződésekor, szinkron vagy szinkron módon, elindítsunk egy tetszőleges utasítást. |
| destroy() | boolean-nel tér vissza, ami azt mutatja meg, hogy az adott folyamat leállítási kérelme sikeresen fel lett-e dolgozva. |
ProcessHandle.Info interfész
Egy folyamatra egy adott időpillanatban vonatkozó információit tartalmazza. Ezek az információk korlátozottak lehetnek az információkat igénylő folyamatra vonatkozó operációs rendszeri jogosultságok függvényében.
| ProcessHandle.Info metódus | Leírás |
| arguments() | Az adott folyamat argumentumait tartalmazó String tömböt tartalmazó Optional objektummal tér vissza. |
| command() | Az adott folyamathoz tartozó alkalmazás nevét tartalmazó Optional-lel tér vissza. |
| commandLine() | Az adott folyamathoz tartozó parancssort tartalmazó Optional-lel tér vissza. |
| startInstant() | Az adott folyamat indításának pillanatát tartalmazó Optional-lel tér vissza. |
| totalCpuDuration() | Az adott folyamat által felhasznált CPU-időt tartalmazó Optional-lel tér vissza. |
| user() | Az adott folyamat felhasználóját tartalmazó Optional-lel tér vissza. |
Példa
public static void main(String[] args) throws InterruptedException, IOException {
printProcessInfo("main", ProcessHandle.current());
Process process = new ProcessBuilder("notepad.exe", "C:/teszt.txt").start();
printProcessInfo("notepad", process.toHandle());
process.waitFor();
printProcessInfo("notepad", process.toHandle());
}
private static void printProcessInfo(String processDescription, ProcessHandle processHandle) {
System.out.println("---------- Információk a(z) " + processDescription + " folyamatról ----------");
System.out.printf("Folyamat azonosító (PID): %d%n", processHandle.pid());
ProcessHandle.Info info = processHandle.info();
System.out.printf("Parancs: %s%n", info.command().orElse(""));
String[] arguments = info.arguments().orElse(new String[] {});
System.out.println("Argumentumok:");
for (String argument : arguments) {
System.out.printf(" %s%n", argument);
}
System.out.printf("Parancssor: %s%n", info.commandLine().orElse(""));
System.out.printf("Indítási idő: %s%n", info.startInstant().orElse(Instant.now()).toString());
System.out.printf("Futási idő: %sms%n", info.totalCpuDuration().orElse(Duration.ofMillis(0)).toMillis());
System.out.printf("Felhasználó: %s%n", info.user().orElse(""));
System.out.println();
}
Összefoglalás
A Java 9 process API újításai segítségével szebb kódot írhatunk. A korábbi verzióban bevezetett ProcessBuilder is jelentős lépés volt a helyes irányba, de az új lehetőségek, amiket az új interfészek, illetve az azokat megvalósító osztályok biztosítanak, fontos új eszközöket adnak a programozók kezébe, amikkel könnyebben kezelhetővé váltak a natív folyamatok.
Ha a többi Java 9-es újítás is érdekel, akkor böngészd bátran a többi blog posztot is ebben a témában!
A hivatalos javadoc-ban minden további részletet megtalálsz:
ProcessBuilder, Process, ProcessHandle, ProcessHandle.Info, CompletableFuture.


 Ahhoz, hogy megértsük, milyen új képességekre teszünk szert a Java 9 kibővült eszközkészletével, előbb érdemes megnéznünk az előzményeket.
Ahhoz, hogy megértsük, milyen új képességekre teszünk szert a Java 9 kibővült eszközkészletével, előbb érdemes megnéznünk az előzményeket. Néha úgy érzem kár lefordítani magyarra a fontosabb angol szakkifejezéseket. Talán most is jobban tettem volna, ha link time-nak hagyom.
Néha úgy érzem kár lefordítani magyarra a fontosabb angol szakkifejezéseket. Talán most is jobban tettem volna, ha link time-nak hagyom.
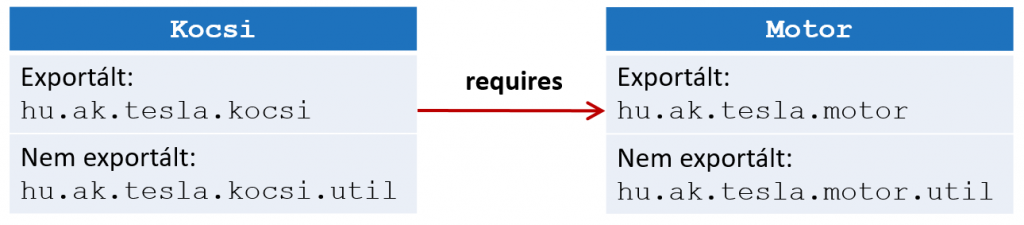
 Ezen új feature-ök segítségével újonnan írt programjainkban újabb szinten megvalósulhat az OOP egyik alapelve, az egységbezárás (encapsulation), aminek az előnyei régóta jól ismertek.
Ezen új feature-ök segítségével újonnan írt programjainkban újabb szinten megvalósulhat az OOP egyik alapelve, az egységbezárás (encapsulation), aminek az előnyei régóta jól ismertek. A Java 9 legmeghatározóbb eleme a
A Java 9 legmeghatározóbb eleme a